When you want to import a GitHub issue into another issue management system, use the GitHub CLI to export the issues to a file and then import that file into another issue management system.
Upon evaluating different import methods available in JIRA, I found CSV files to be the easiest format to import. Therefore, I exported GitHub issues into a CSV file.
This article shares how I exported to a CSV file then and the trial and error process I went through to get there.
To execute the steps described in this article, you must first install the GitHub CLI. Refer to the following article for instructions on installing the GitHub CLI.
Issue is in the repository
Unlike a dedicated issue management system like JIRA, GitHub issues are repository-based. Therefore, when exporting, you work on a repository-by-repository basis.
Clone Repository
Clone the repository containing the issue you wish to export. No special options are needed, and the cloning process can be conducted as usual.
% gh repo clone ExampleUser/ExampleRepoOnce the cloning is complete, go into the repository directory.
% cd ExampleRepoExport issues
To export an issue, utilize the GitHub CLI to retrieve the issue. The author had never exported an issue before, so it took a lot of trial and error. This article uses an issue from the repository in my book “基礎から学ぶARKit” as an example.

Retrieve issues in batches
The command gh issue list can be run to retrieve a batch of issues at once. I began by executing this command.
% gh issue list
Showing 1 of 1 open issue in akirark/LearnARKit
#34 読者質問への回答を行う about 3 minutes agoSpecify status
I retrieved the issues, but the number of issues was small. So I checked the gh issue list options and found that the state option can be used to specify the state of the issue to be output.
The following three values are available.
- open: Only open issues
- closed: Only closed issues
- all: All issues
When exporting to a CSV file, I want to export open and closed issues to separate files, so that I would use open and closed, but I used all because I want to display them in the shell first.
% gh issue list --state all
Showing 26 of 26 issues in akirark/LearnARKit that match your search
#34 読者質問への回答を行う about 10 minutes ago
#32 CHAPTER01/00_Assets/Chairフォルダを... bug about 5 months ago
...This repository has a small number of issues, but the output was generated regardless of the state.
Specify the number of items
This repository has a small number of issues, so there is no need to specify this. Still, a large repository will only output 30 issues unless the limit option is used to specify the maximum number of outputs. For example, the following will output up to 1000 issues.
% gh issue list --limit 1000 --state allOutput in JSON
Before exporting to a CSV file, gh will output the issue in JSON. Use the json option to output in JSON.
% gh issue list --limit 1000 --state all --jsonWhen I run it, I get the following error message.
Specify one or more comma-separated fields for `--json`:
assignees
author
body
closed
closedAt
comments
createdAt
id
labels
milestone
number
projectCards
projectItems
reactionGroups
state
title
updatedAt
urlWhen outputting in JSON, it seems necessary to specify the fields to be output; it is sufficient to export the information you wish to include in the CSV, so the author decided to export the following fields.
- number: The issue ID
- title
- body
- state
- createdAt: Created date
- updatedAt: Updated date
- milestone
Perform the following.
% gh issue list --limit 1000 --state all --json 'number,title,body,state,createdAt,updatedAt,milestone'
[
{
"body": "読者質問があったので回答する。\r\nOSのバージョンが上がった影響があった様子である。\r\n",
"createdAt": "2023-05-12T13:23:49Z",
"milestone": {
"number": 1,
"title": "support_revision_1",
"description": "",
"dueOn": null
},
"number": 34,
"state": "OPEN",
"title": "読者質問への回答を行う",
"updatedAt": "2023-05-12T13:51:16Z"
},
...The issue was output in JSON.
Transforme to CSV
JQ is a JSON processing and formatting tool that allows you to specify the processing and formatting methods available for the jq option of gh, and gh outputs the processed and formatted results according to the specified methods.
We can use it to convert JSON to CSV. The code to transform to CSV is the following.
map([.number, .state, .createdAt, .updatedAt, .milestone.title, .title, .body] | @csv) | join("\n")This is specified in gh with the jq option.
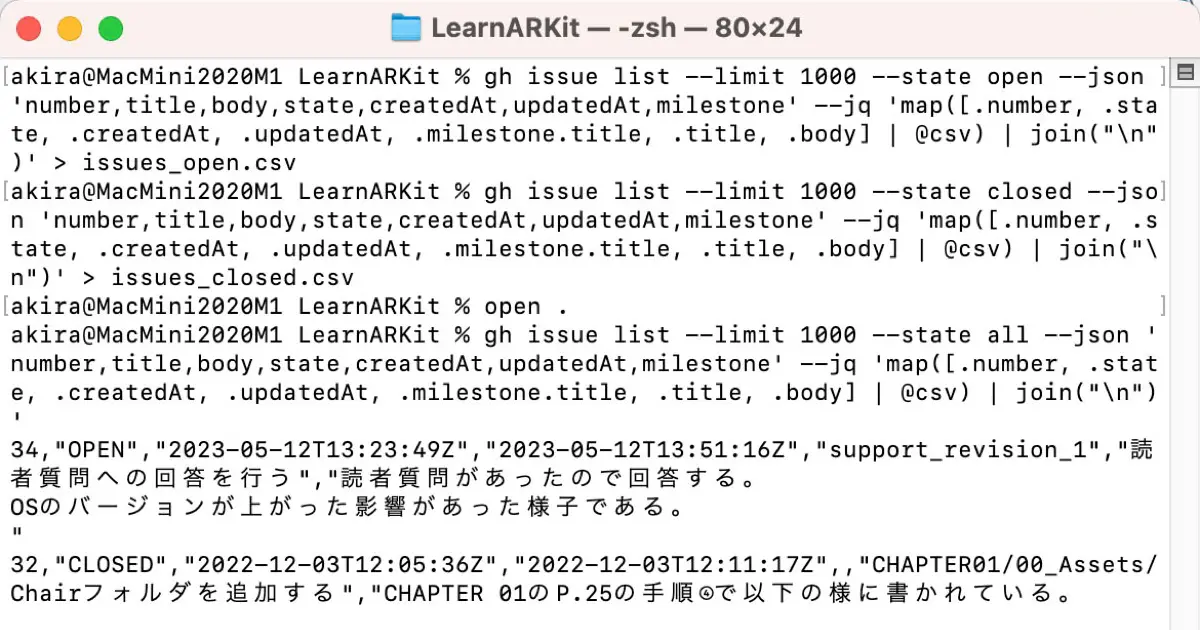
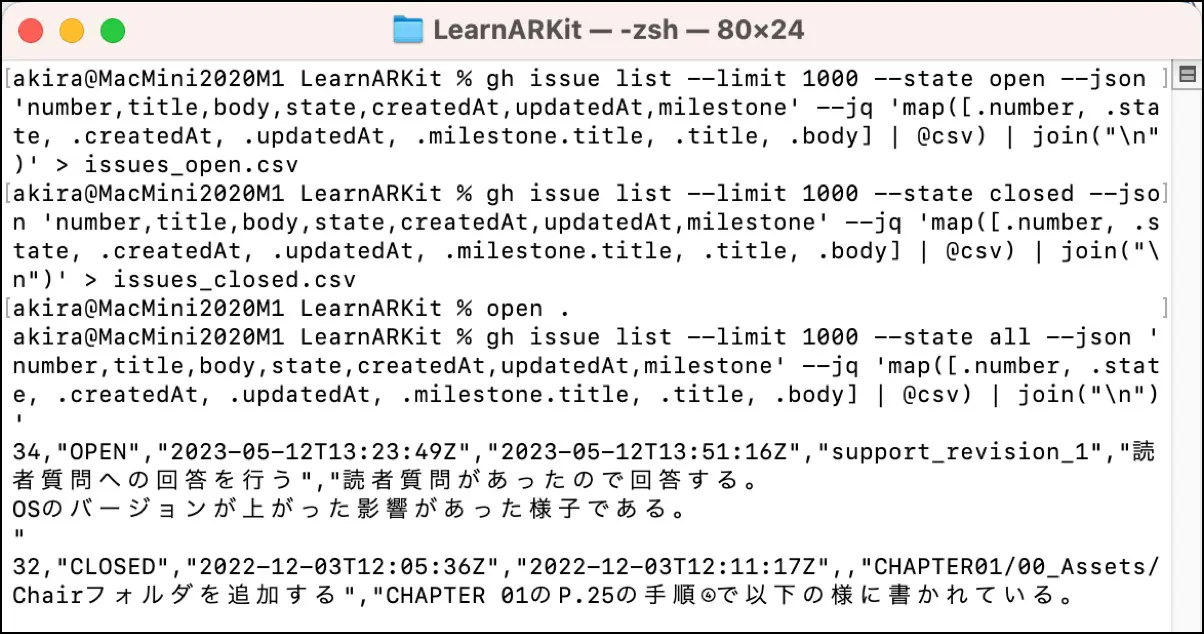
% gh issue list --limit 1000 --state all --json 'number,title,body,state,createdAt,updatedAt,milestone' --jq 'map([.number, .state, .createdAt, .updatedAt, .milestone.title, .title, .body] | @csv) | join("\n")'
34,"OPEN","2023-05-12T13:23:49Z","2023-05-12T13:51:16Z","support_revision_1","読者質問への回答を行う","読者質問があったので回答する。
OSのバージョンが上がった影響があった様子である。
"
...The rest is redirected to a file instead of a shell, and the states open and closed are written to separate files for convenience when importing into JIRA.
Investigation of the jq command (added May 13, 2023)
I used ChatGPT to investigate the formatting and processing methods specified in the jq option. I have included the research process in this article.
Summary
Using the GitHub CLI, I exported GitHub issues to CSV by following the issue Get -> JSON -> CSV process. The repository I wanted to migrate this time had a small number of issues, so the method described in this article worked fine.
However, suppose the number of issues exceeds the number that can be written out at one time on the gh issue list. In that case, splitting the list into multiple issues may be necessary.
Also, since comments are multiple and nested, it is impossible to convert them to CSV. Therefore, if you want to export comments, it is better to export them in JSON.